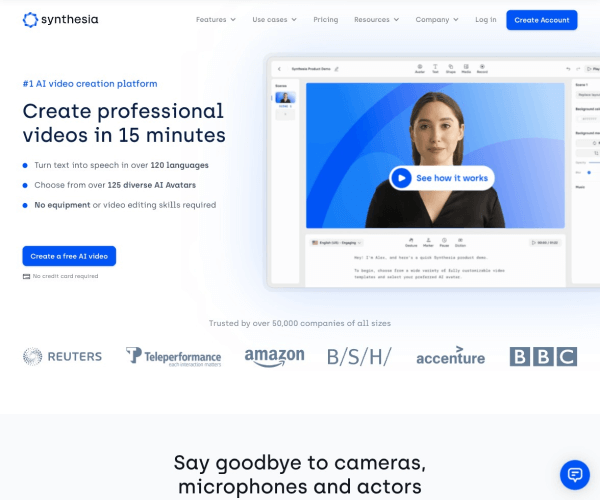
Synthesia简介:AI驱动的视频生成平台
Synthesia是由英国公司Speech2Face开发的一款AI驱动的视频生成平台,成立于2016年,旨在通过人工智能技术简化视频内容的创作过程。用户只需输入文本或语音指令,即可快速生成逼真的人脸动画和定制化视频,无需专业设备或演员参与。这一工具现已成为企业营销、教育、客户服务等领域的高效内容生产工具。
---
核心功能与技术特点
1. 视频自动生成
用户可输入文字或语音脚本,Synthesia通过AI算法生成对应的人脸动画视频,支持调整角色形象(如性别、年龄、表情)、背景、服装等参数,实现高度定制化。输出视频支持多种分辨率和格式,最高可达4K。
2. 多语言与实时渲染
支持超过30种语言的语音合成和字幕生成,结合实时渲染技术,可在数分钟内完成从脚本到视频的生成。其AI模型能够模拟自然语言节奏和情感表达,提升视频的拟真度。
3. 企业级功能扩展
包括模板库、品牌元素嵌入、数据追踪分析等功能。企业用户可通过API集成Synthesia到营销自动化流程,实现个性化视频的批量生成与分发。
---
技术解析:AI与生成模型的协同
Synthesia的核心技术基于深度学习与生成对抗网络(GANs),结合以下技术模块:
- 语音合成(TTS):通过神经网络将文本转化为自然语音,支持音色、语调调整。
- 面部动画生成:利用GANs生成与语音同步的口型、表情和头部动作,确保动作流畅真实。
- 3D角色建模:提供数百个预设虚拟形象,用户也可上传自定义3D模型。
处理流程:用户输入文本→AI解析并生成语音→驱动面部动画→合成视频→导出成品。该系统能够在云端实时处理,显著缩短传统视频制作的周期。
---
发展历程与关键里程碑
- 2016年:Speech2Face团队推出首款原型产品,专注于将文本转化为简单面部动画。
- 2018年:发布Synthesia 2.0,新增多语言支持和企业API接口,用户量增长200%。
- 2020年:引入“虚拟形象生成器”,允许用户自定义角色外貌与服装。
- 2022年:完成B轮融资,资金用于开发高保真视频渲染技术和动态场景生成。
- 2024年:推出Synthesia Pro版,支持4K视频输出与实时协作编辑功能。
关键人物:
- Antony Thomas(CEO):主导产品从概念到商业化落地,推动企业级解决方案开发。
- Dr. Li Wei(CTO):负责AI算法优化,尤其在语音与面部同步技术上取得突破。
---
应用场景与市场影响
1. 企业营销
- 案例:某全球科技公司使用Synthesia为不同地区用户生成本地化产品介绍视频,成本降低70%,转化率提升35%。
- 功能优势:快速响应市场变化,如节日营销、危机公关等场景。
2. 教育与培训
教育机构利用该平台创建交互式教学视频,例如虚拟讲师演示复杂概念,或模拟客户服务对话场景,提升学习效率。
3. 客户服务
企业可自动生成个性化支持视频,例如故障排除指南或账户操作说明,替代部分人工服务需求。
---
行业影响与未来趋势
Synthesia的出现推动了“视频即服务”(VaaS)模式的普及,降低了专业视频制作的门槛。据2025年行业报告,其市场占有率在AI视频生成领域位居全球前三,用户包括Adobe、HubSpot等头部企业。未来趋势可能包括:
- AI生成视频的法律与伦理规范:需应对版权、身份伪造等问题。
- 虚实融合增强:结合AR/VR技术,提供沉浸式视频体验。
- 个性化定制深化:基于用户数据生成高度个性化的动态内容。
Synthesia不仅改变了内容创作的效率,更重新定义了视频作为沟通媒介的可能性,标志着AI在创意产业中的深入应用。
应用截图